Entity Clarity: Wat AI-modellen van je shop verwachten
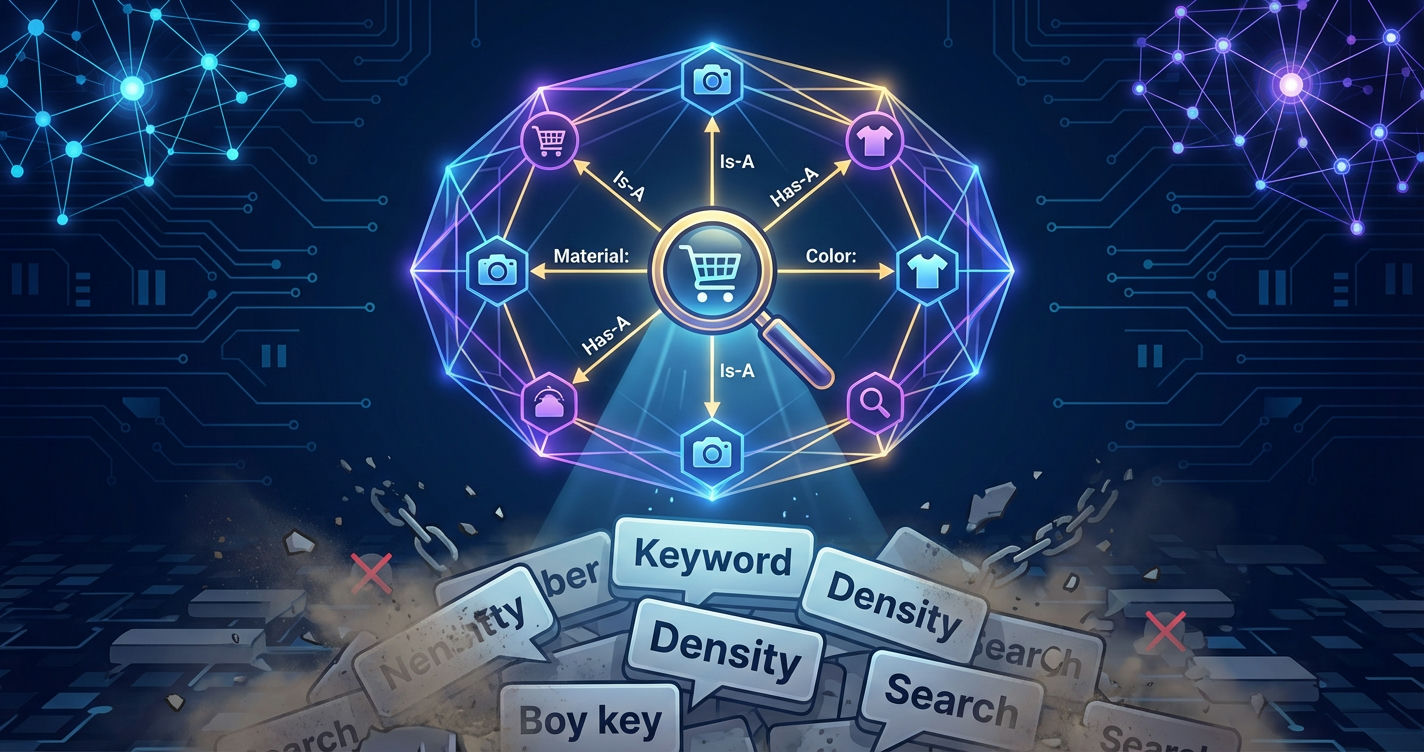
Entity Clarity in plaats van zoekwoorddichtheid: Wat AI-modellen echt van je shop verwachten
Het tijdperk van klassieke zoekmachinemarketing, waarin ranking primair werd bepaald door de wiskundige verhouding van trefwoorden (zoekwoorddichtheid) en het pure aantal backlinks, nadert zijn einde. Met de snelle opkomst van Large Language Models (LLM's) is de waarde van zichtbaarheid verschoven.
Vandaag luidt het doorslaggevende criterium niet langer: "Hoe vaak staat de term op de pagina?", maar: "Worden de entiteiten duidelijk geïdentificeerd en is de informatie geverifieerd betrouwbaar?".
Van zoektermvolume naar het entiteit-paradigma
AI-modellen zoeken naar "Entity Clarity" en "Verified Trust". Een LLM leest tekst niet als een simpele reeks tekens, maar probeert de concepten die in de tekst zijn opgenomen, weer te geven. Een entiteit is een eenduidig identificeerbaar object – een persoon, een merk, een specifiek product of een locatie.
Klassieke SEO vroeg: Hoe vaak komt "hardloopschoenen kopen" voor? AI vraagt: Is "Pro-Run" als merk eenduidig identificeerbaar? Bestaat er een vermelding in een Knowledge Graph? Komen de productgegevens overeen met externe bronnen?
Wanneer een AI-zoekmachine zoals Perplexity of ChatGPT een aanbeveling doet, combineert het informatie uit verschillende bronnen. Shops waarvan de entiteiten duidelijk zijn gedefinieerd, worden bij voorkeur geciteerd — niet omdat ze meer zoekwoorden hebben, maar omdat de AI ze kan classificeren als een betrouwbare informatiebron.
AI plaatst je niet zomaar in een ranglijst – het vertrouwt je, of het doet het niet.
Entity Recognition: Hoe AI je merkidentiteit begrijpt
De centrale drijfveer voor Entity Clarity is de implementatie van Schema Markups (Structured Data). Via Schema-data spreek je direct de taal van de databases van de AI.
Zonder gestructureerde data moet een LLM de volledige paginatekst analyseren en zelf proberen entiteiten te extraheren — een foutgevoelig proces. Met correcte Schema.org-markup daarentegen levert u de AI de entiteiten op een presenteerblaadje: naam, type, relaties en attributen zijn eenduidig gecodeerd.
Een concreet voorbeeld: Als uw shop "Natuurcosmetica Müller" heet, maar op de website staat alleen "Welkom bij ons", heeft de AI een probleem. Met een Organization-schema inclusief name, url, logo en sameAs-koppelingen naar uw sociale-mediaprofielen daarentegen, kan de AI uw merk onmiddellijk indelen.
De Knowledge Graph: Denken in relaties
Kunstmatige intelligentie visualiseert informatie in een Knowledge Graph — een netwerk van entiteiten en hun onderlinge relaties. Typische relaties:
- related_to: Welke thema's zijn gekoppeld aan uw merk?
- belongs_to: Tot welke overkoepelende bedrijfscategorie behoort uw shop?
- includes: Welke specifieke kenmerken omvat uw aanbod?
- manufactured_by: Wie produceert de producten?
- certified_by: Welke certificeringen of keurmerken bevestigen de kwaliteit?
Strategische prioritering van Schema Types
Organisatie: De basis van merkidentiteit
De startpagina moet verplicht worden gemarkeerd met het type Organization. Hiermee definieert u uw merk als een zelfstandige entiteit in de Knowledge Graph. Verplichte velden:name, url, logo, contactPoint en sameAs (links naar Wikipedia, LinkedIn, sociale media).
Persoon: E-E-A-T via auteurs-entiteiten
Auteurspagina's moeten het type Person gebruiken voor Experience, Expertise, Authoritativeness en Trustworthiness. Vooral voor bloginhoud en wegwijzers is het cruciaal dat de AI de auteur als vakkundig competent kan classificeren.Product: Zichtbaarheid in de AI-winkelwereld
In e-commerce is het Product-schema essentieel. Alleen met volledige productgegevens (naam, SKU, GTIN, prijs, beschikbaarheid, beoordelingen) kan uw product verschijnen in AI-gegenereerde aanbevelingen.Article & FAQPage: Directe antwoordextractie
FAQPage dient als bron voor directe antwoordextractie. Als een gebruiker een vraag stelt die exact overeenkomt met een van uw veelgestelde vragen, neemt de kans op een directe citatie aanzienlijk toe.HowTo: Stap-voor-stap extractie
Handleidingen in het HowTo-formaat stellen de AI in staat om complexe processen als nuttige snippets weer te geven. Elke stap wordt afzonderlijk geïndexeerd en kan dienen als een zelfstandig antwoord.Doorslaggevende Entiteitseigenschappen voor maximaal vertrouwen
- sameAs: Linkt uw entiteit met andere gezaghebbende profielen (Wikipedia, Social Media). Dit is een van de sterkste vertrouwenssignalen voor AI-modellen, omdat het externe validatie mogelijk maakt.
- about & mentions: Definieer waar het in de kern over gaat en welke entiteiten worden genoemd. Zo kan de AI de thematische context beter begrijpen.
- author & publisher: Leggen het verband tussen inhoud en de verantwoordelijke eenheid. Zonder deze eigenschappen zweeft de inhoud contextloos in de digitale ruimte.
- dateModified: Signaleert aan de AI dat de informatie nog relevant is. Verouderde inhoud wordt systematisch afgewaagd.
- hasOfferCatalog: Koppel uw organisatie aan het productaanbod en creëer een directe brug tussen merk en assortiment.
Praktische checklist voor Entity Clarity
- ✅ Organisatie-schema op de startpagina met
sameAs-links - ✅ Product-schema op elke productpagina met GTIN/SKU
- ✅ FAQPage-schema op hulp- en informatiepagina's
- ✅ Persoon-schema voor blogauteurs en experts
- ✅ Consistente naamgeving via alle kanalen
- ✅ Regelmatige update van
dateModified
Conclusie: Vertrouwen in plaats van ranking
AI-modellen rangschikken u niet volgens wiskundige formules uit het verleden – zij beoordelen uw geloofwaardigheid en identificeerbaarheid. Zorg voor duidelijkheid in uw structuur, verifieer uw identiteit via externe referenties en onderhoud uw entiteiten met dezelfde zorg als uw voorraden. Entity Clarity is geen eenmalige taak, maar een voortdurend proces — net als het vertrouwen dat u ermee opbouwt.